Track 01 / Computer Vision
Bounding boxes, polygons, keypoints, segmentation, video tracking — the highest-volume track. Operators specialised by domain: autonomy, retail analytics, medical imaging, agri-tech.
Techniques
Every technique runs through the same multi-tier review pipeline. Schema changes. The discipline doesn’t.
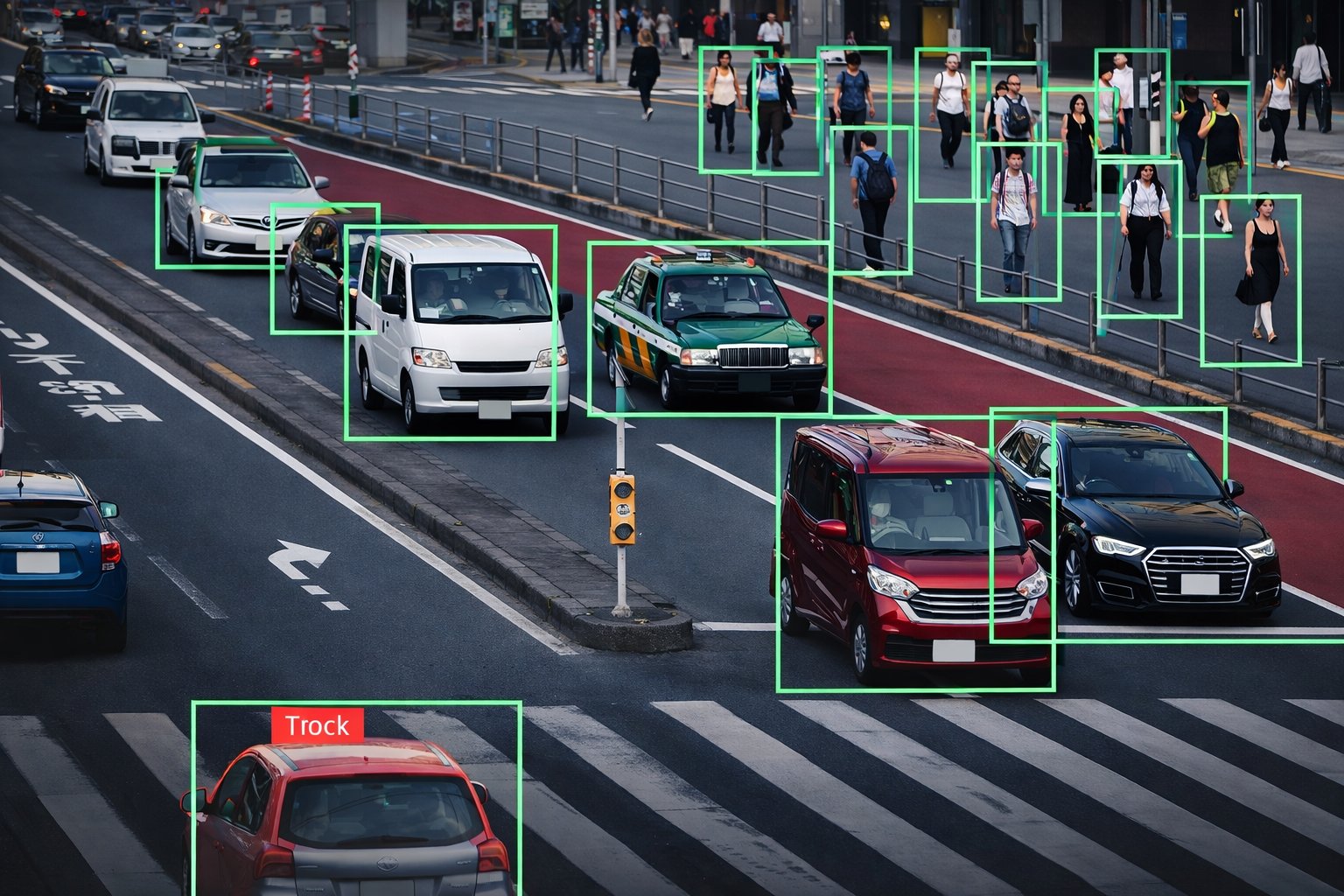
Class-labelled bounding boxes with occlusion and truncation flags as part of the schema. The workhorse of object detection pipelines — ADAS, retail shelf, agri-pest, surveillance.


Vertex-level polygons for irregular shapes where bounding boxes waste context. Retail product shelving, medical lesions, agri-crop rows, defect detection on manufactured goods.
Dense pixel-level labels for scene understanding — drivable area, vegetation, person, vehicle, infrastructure. Multi-class masks stitched so no pixel is left unlabeled between classes.

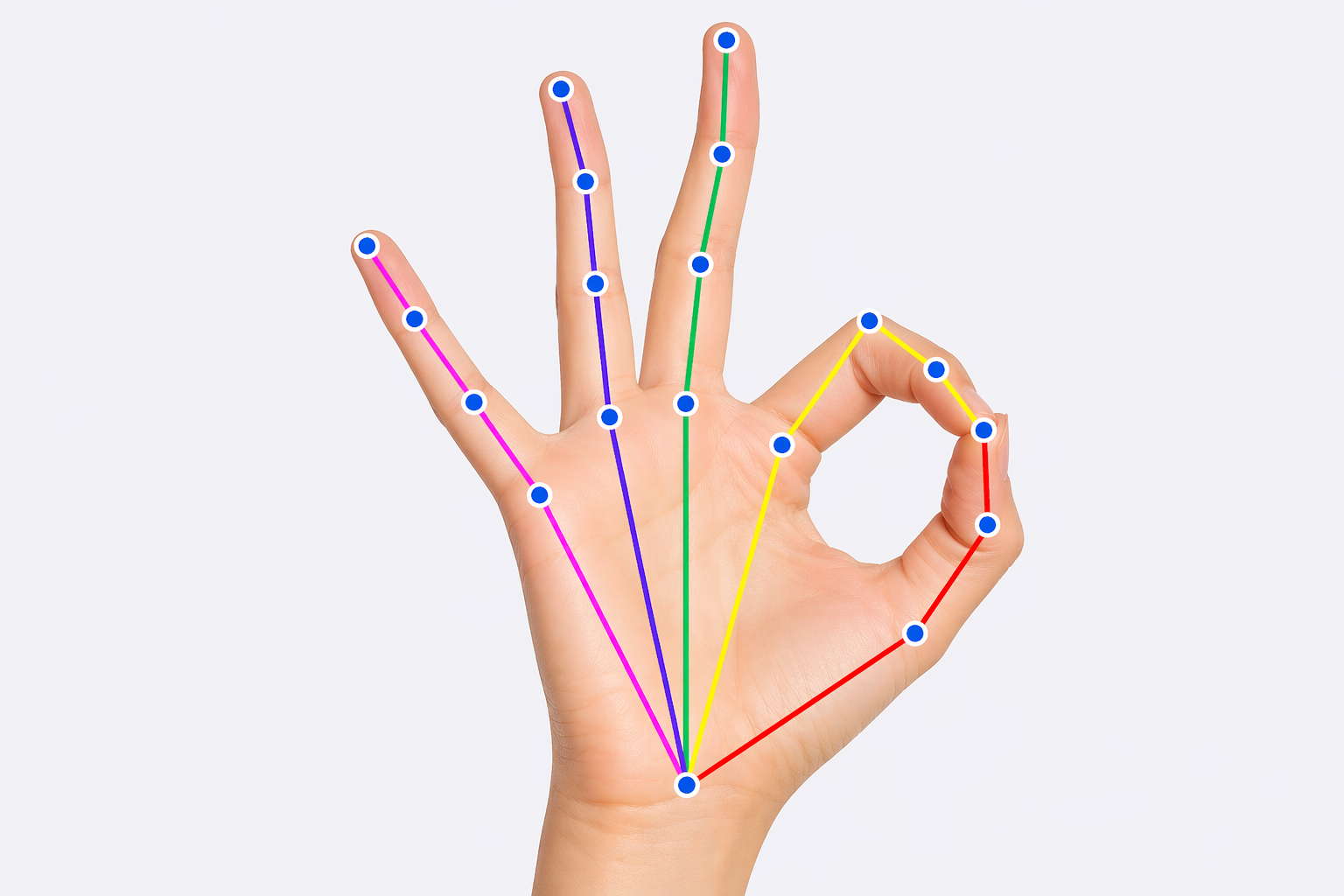
Skeletal landmark annotation for body, face, and hand. Standard topologies (COCO, OpenPose) or client-defined skeletons. Occlusion visibility flags per keypoint.
Multi-object tracking with stable identity across frames, re-entry handling, and keyframe interpolation. Reviewers trained to resolve occlusion re-ID — not just the first frame.
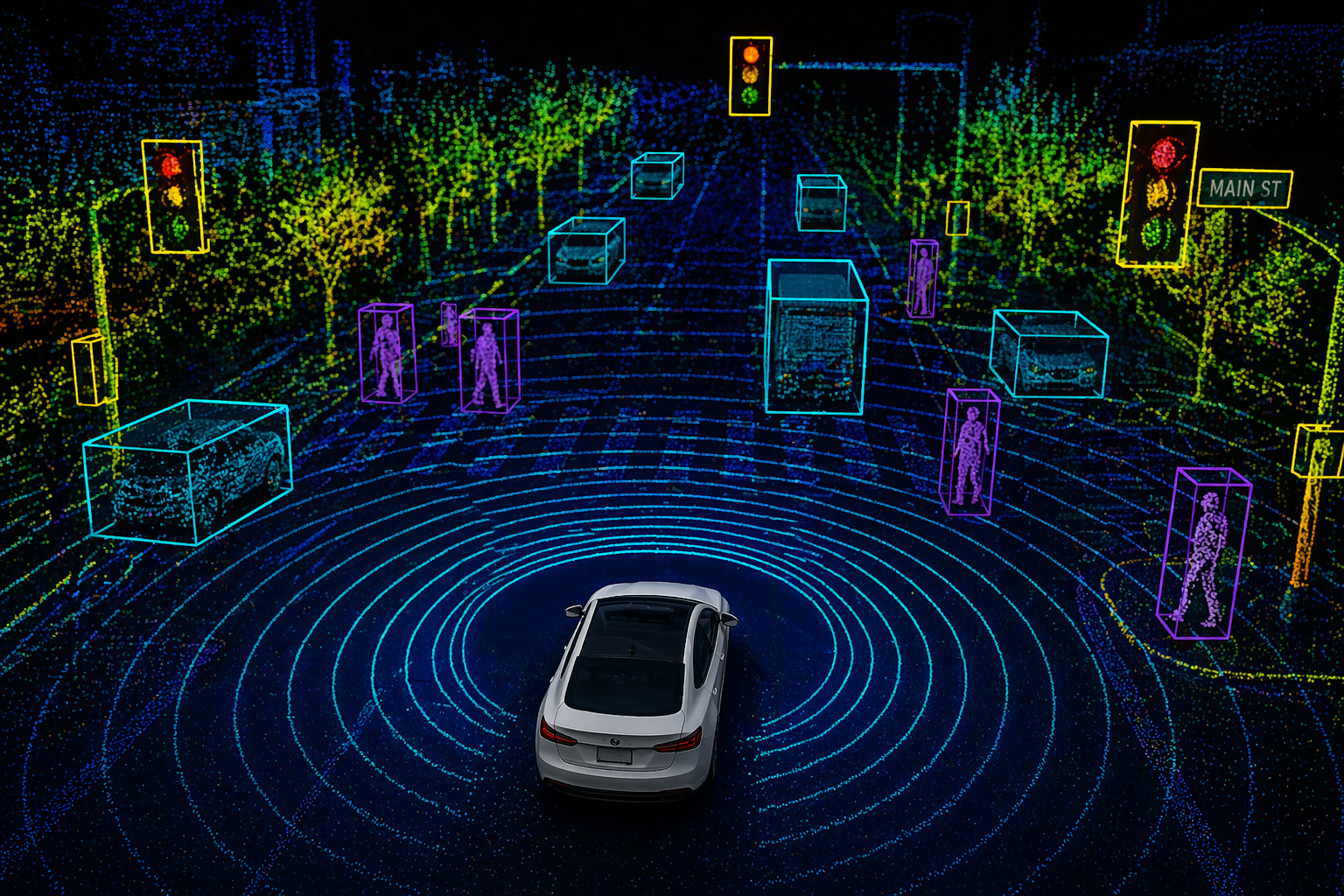
2D-projected 3D cuboids for AV stacks without LiDAR. Encodes heading and object size from monocular frames. Often used as a bridge to full 3D labelling.
Where we’ve delivered
CV operators are pooled by domain — the same reviewer who can label medical lesions isn’t also labelling AV dashcam. Domain trains judgment.
Dashcam, surround, sensor-fused datasets for perception training. Night / rain / edge-case prioritised.
Planogram compliance, product recognition, stock-out detection. High SKU density, long-tail classes.
Lesion, organ, and anatomical landmark annotation under reviewer oversight. PHI-safe environment.
Crop row, weed, pest, and yield-estimation labels from drone and satellite imagery. Multi-season.
Schema specifics
Your schema is the source of truth. These are the schema surfaces that most often need tightening before a pilot runs clean.
Multi-level class trees with inheritance. Resolved before calibration, versioned through the engagement.
Tri-state or percent bands rather than binary flags — carries more useful signal downstream.
Rules for when a crowd becomes a single "crowd" region rather than N instances.
How to label objects cut by the frame — extend-the-box, clip-to-frame, or skip.
Minimum vertex density tied to object type. Pedestrians ≠ trucks ≠ medical lesions.
When a disappearing-then-reappearing object keeps its ID vs. takes a new one.
Questions we get
Yours. We train operators to the platform you already run — CVAT, Label Studio, V7, Labelbox, Encord, Scale, SuperAnnotate, Roboflow, or an internal tool. No migration required.
Typically two to four weeks from scope to steady-state, depending on schema complexity. Pilot runs against a co-drafted gold set; schema tightens before scaling headcount.
Route-to-client, not guess-and-log. Ambiguous frames surface to your data lead with a proposed resolution and are not silently labelled wrong.
Yes, for medical, defense, and regulated financial datasets. Operators work inside the secured environment with audited access. Specific envelope confirmed at scope.
Written per engagement. An IAA threshold against a gold reference co-drafted with your team — miss it and rework is on us.
Other annotation tracks
Computer vision sits alongside two other tracks under the same QA discipline and the same operating model.
Scope with us
We scope operators, schema work, and a written accuracy threshold together — and run a pilot against a co-drafted gold set before you commit to steady-state volume.